在中国,AI医疗市场规模从2019年的27亿元迅猛增长至2023年的107亿元,预计2028年将突破976亿元,占整个AI行业的比重升至15.4%。在这一进程中,医疗大模型正引领医疗AI向多场景应用迈进,为解决医疗资源分布不均、提高诊疗效率提供了关键的技术支持。
也正是在这样的行业浪潮下,在2025年中国国际医疗器械展览会(CMEF)同期举行的uAInnovation 2025联影创新大会上,联影「元智」医疗大模型的发布尤为引人注目。该医疗大模型不仅在文本方面吸收DeepSeek等通用大模型在处理自然语言、长文本方面的最新进展,还在其他多模态全面深度垂域自研,并通过整合不同模态大模型的能力,可根据不同医疗场景需求孕育出自进化、多模态、自适应的医疗智能体。

该医疗大模型并非单一模型,而是涵盖了医疗文本大模型、医疗语音大模型、医疗视觉大模型、医疗影像大模型以及医疗混合大模型。其中,联影「元智」医疗混合大模型是打破单模态能力边界、适配复杂医疗场景的核心枢纽——它叠加文本、影像、语音、视觉四大模型的功能,具备医疗场景所需的“看、听、想、读”全维度能力,成为连接技术与临床价值的关键桥梁。
在此基础之上孕育而生的介入医生智能体,依托联影「元智」医疗多模态大模型,实现了信息的高效整合及核心参数的量化分析,显著提升了术中的认知效率和决策质量。例如,在精准度要求极高的心脏介入手术中,通过整合CTA、DSA等多模态数据,突破传统2D视野的局限,实现三维血管成像,为术前规划和术中导航提供有力支持,从而显著降低手术风险。
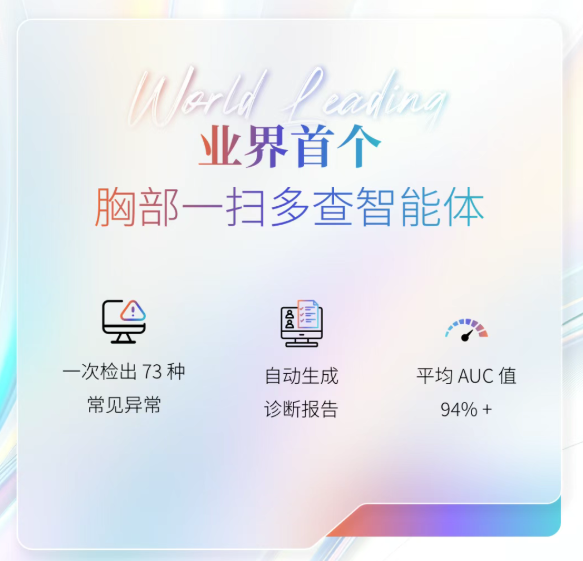
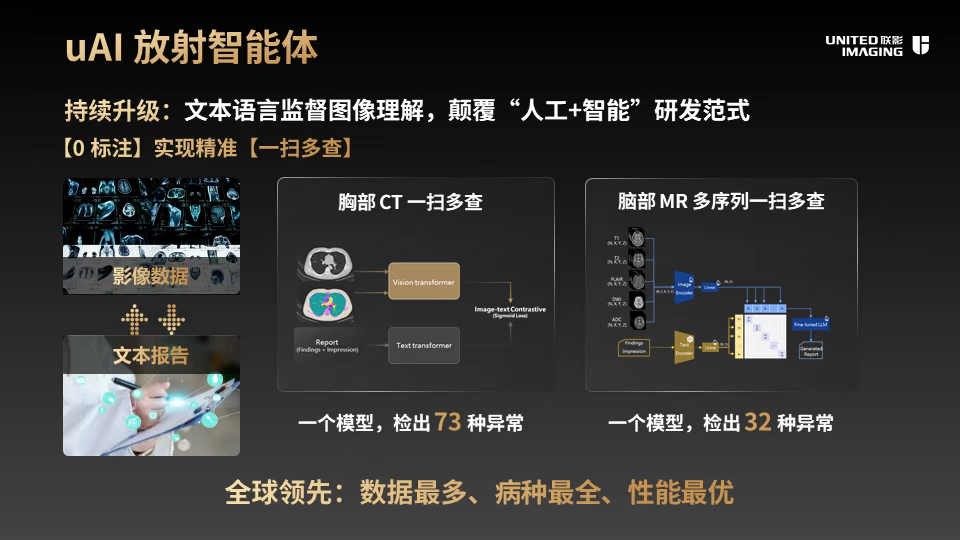
而联影「元智」医疗文本大模型以“专业知识深度+轻量化部署”的双重优势,成为临床文书处理与知识应用的核心支撑。其最鲜明的技术突破在于实现70B参数的轻量化部署——通过将海量医学专业知识注入DeepSeek等通用大模型,在大幅降低算力需求的同时,平衡了推理速度与诊断准确性,适配不同层级医疗机构的硬件条件;「元智」影像大模型依托数千万级医疗影像数据、数十万级精细标注数据,支持10余种主流影像模态的AI智能分析,还可完成300余项影像分割任务,关键任务的准确率均超95%;联影「元智」医疗语音大模型专为复杂医疗场景定制,不仅能在嘈杂环境中精准识别医疗术语,还支持多人对话时的智能声纹分析和身份识别。经影像报告及医疗客服场景测试,其识别水平均达到业界领先水平。
在此基础上孕育而生的放射智能体,融合了「元智」影像、语音及文本大模型的多重能力,通过「看、听、想」的多模态协同作用,实现了从医学图像感知到诊断语言生成的完整闭环;电子病历智能体在病历书写环节中,能够自动生成多种医疗文书,包括入院记录、病程记录和出院小结等。以复旦大学附属中山医院为例,该智能体已在十余个科室成功应用,累计调用次数超过6000次,文书采纳率高达93%。
联影「元智」医疗视觉大模型全面覆盖4D建模、4D高速电影级渲染、医疗视频生成、人体重建等所有视觉能力场景,多项任务达到业内SOTA模型(State-of-the-Art,特定任务或领域表现最优)水平。其客服智能体在「元智」文本与语音大模型的基础上,具备了医学语义理解与自然语言交互能力,能够7×24小时回应患者对疾病、检查流程等多方面的常见问题。
随着人工智能技术和医疗大模型的普惠普及,越来越多的医疗机构开始探索其在实际诊疗中的应用潜力。联影「元智」医疗大模型的推出,无疑为这一进程注入了强劲的动力。