近年来,人工智能与医疗健康的深度融合,正推动医疗诊断迈向智能化、精准化、全流程化的新纪元。尤其是多模态医疗大模型的崛起,打破了传统单一模态分析的局限,为疾病的早期筛查、精准诊断、个体化治疗和全病程预测提供了前所未有的技术支撑。
当前,在医学文本生成方面,多项测试表明,复杂推理能力的通用大模型仍存在幻觉,在诊断精准度上与医生仍有差距,唯有专业训练的垂域、多模态医疗大模型才能既快又优地满足医疗对精准度、个性化的需求。
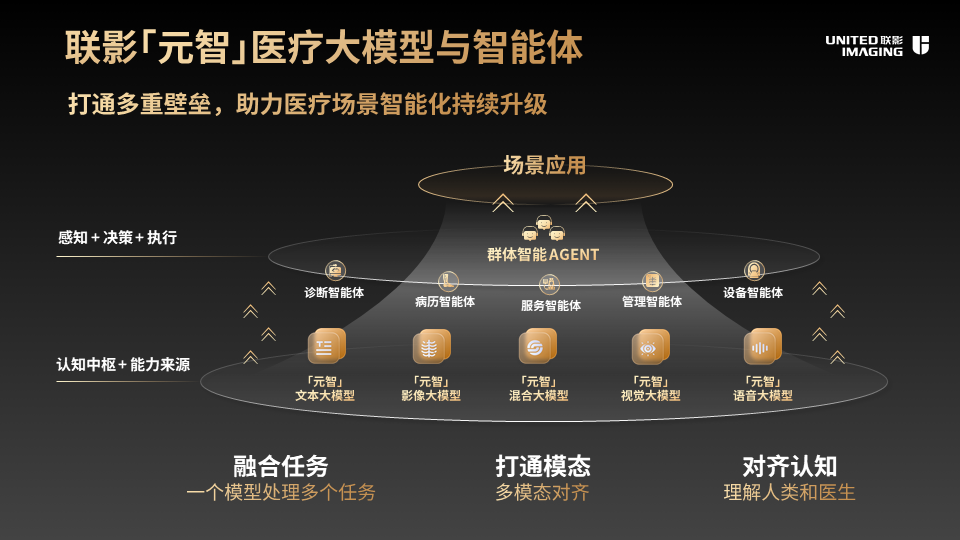
联影智能基于其在医疗AI领域的前瞻布局与技术积淀,推出了全新的「元智」医疗大模型。该模型依托联影智能多年来在医疗垂直领域的深厚积累,尤其凭借其底层数据优势——包括数千万级医疗影像数据与数十万级精细标注数据,以及多模态融合架构,整合了文本、影像、视觉、语音、混合五个大模型,在复杂病灶诊断、多器官分割等关键任务中实现性能突破,多项指标显著超越行业最优水平。
联影「元智」医疗文本大模型可注入所接入的DeepSeek等通用大模型,实现仅需70B的轻量化部署,满足不同医疗机构的要求,实现算力、反应速度和准确率的三者平衡;
联影「元智」医疗影像大模型基于数千万级医疗影像数据、数十万级精细标注数据进行训练,支持10+模态分析、300+分割任务,在关键任务中精准度超95%,凭借在医疗垂直领域的积累,实现影像大模型壁垒级全能领航;

联影「元智」医疗视觉大模型全能覆盖4D建模、4D高速电影级渲染、医疗视频生成、人体重建等全部视觉能力场景,多项任务达业内SOTA模型(State-of-the-Art,特定任务或领域表现最优)水平;
联影「元智」医疗语音大模型为复杂的医疗场景定制,不仅能在嘈杂环境中精准识别医疗术语,还支持多人对话时的智能声纹分析、身份识别。经影像报告及医疗客服场景测试,其识别水平均达到业界领先;
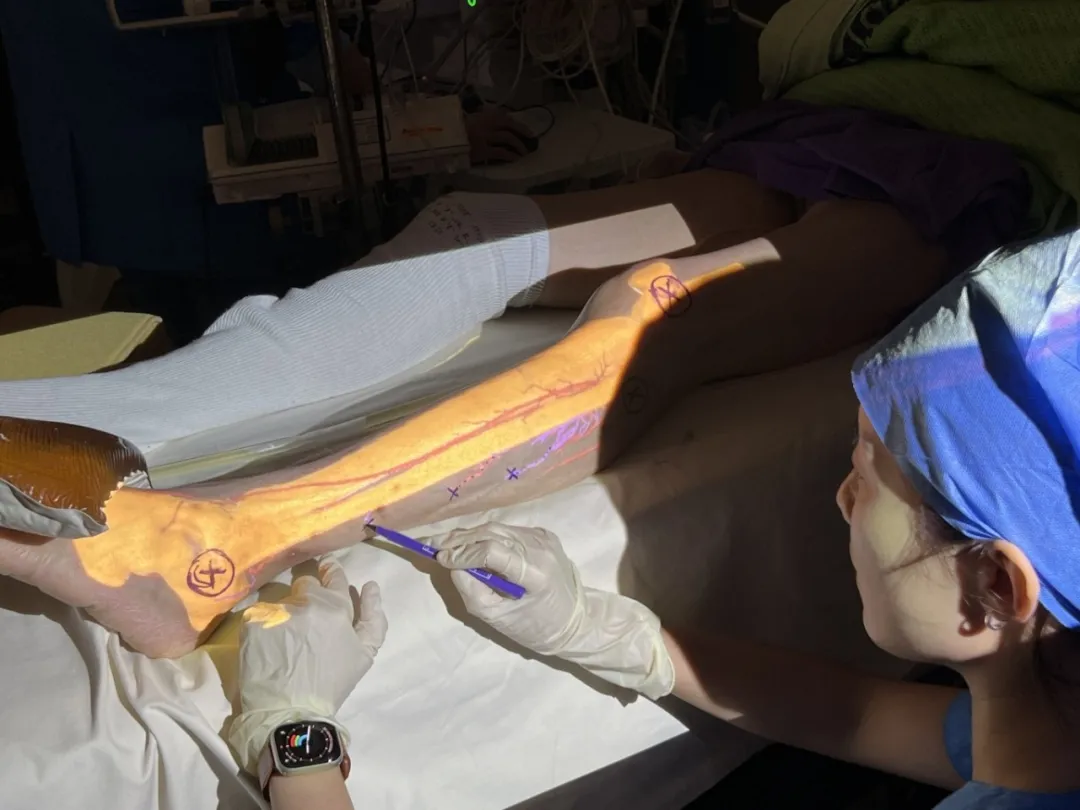
联影「元智」医疗混合大模型融合视觉、语音、影像、文本多模态,具备「看」「听」「想」「读」的能力,该混合大模型已在业内率先落地,应用于复杂的医疗场景——在联影智能业界首创的AI+AR引导的皮瓣移植手术中,依靠混合大模型驱动,目前已在香港、上海落地数十例。
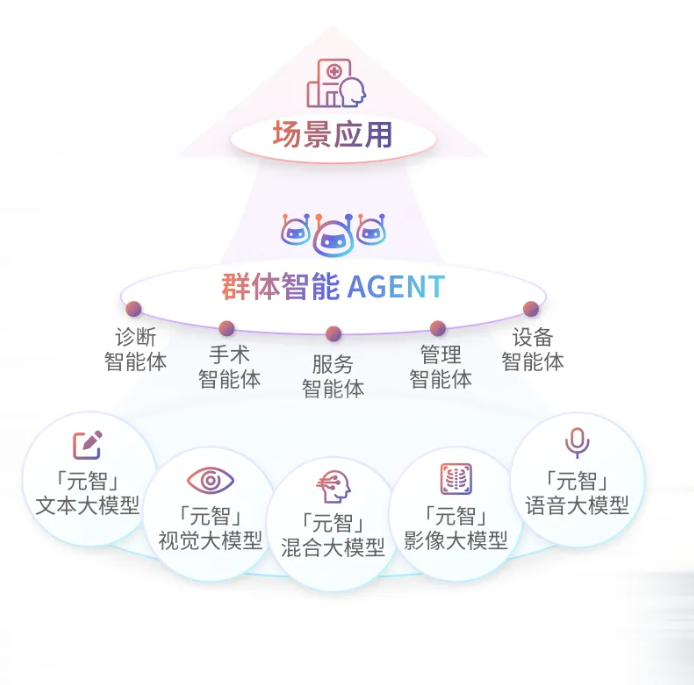
基于该多模态医疗大模型,孕育出的十余款医疗智能体,覆盖了诊断、手术、服务、管理等细分医疗场景,具备超强的自进化、多模态、自适应能力,还能互相联动、协同共生,以群体智能满足全院级数智化建设需求。
未来,随着多模态医疗大模型融合能力的持续深化,这一技术底座必将为医疗智能化注入更强劲的动力,推动精准医疗、个性化服务走向更广阔的实践场,让技术与医疗的共生绽放更深远的价值。